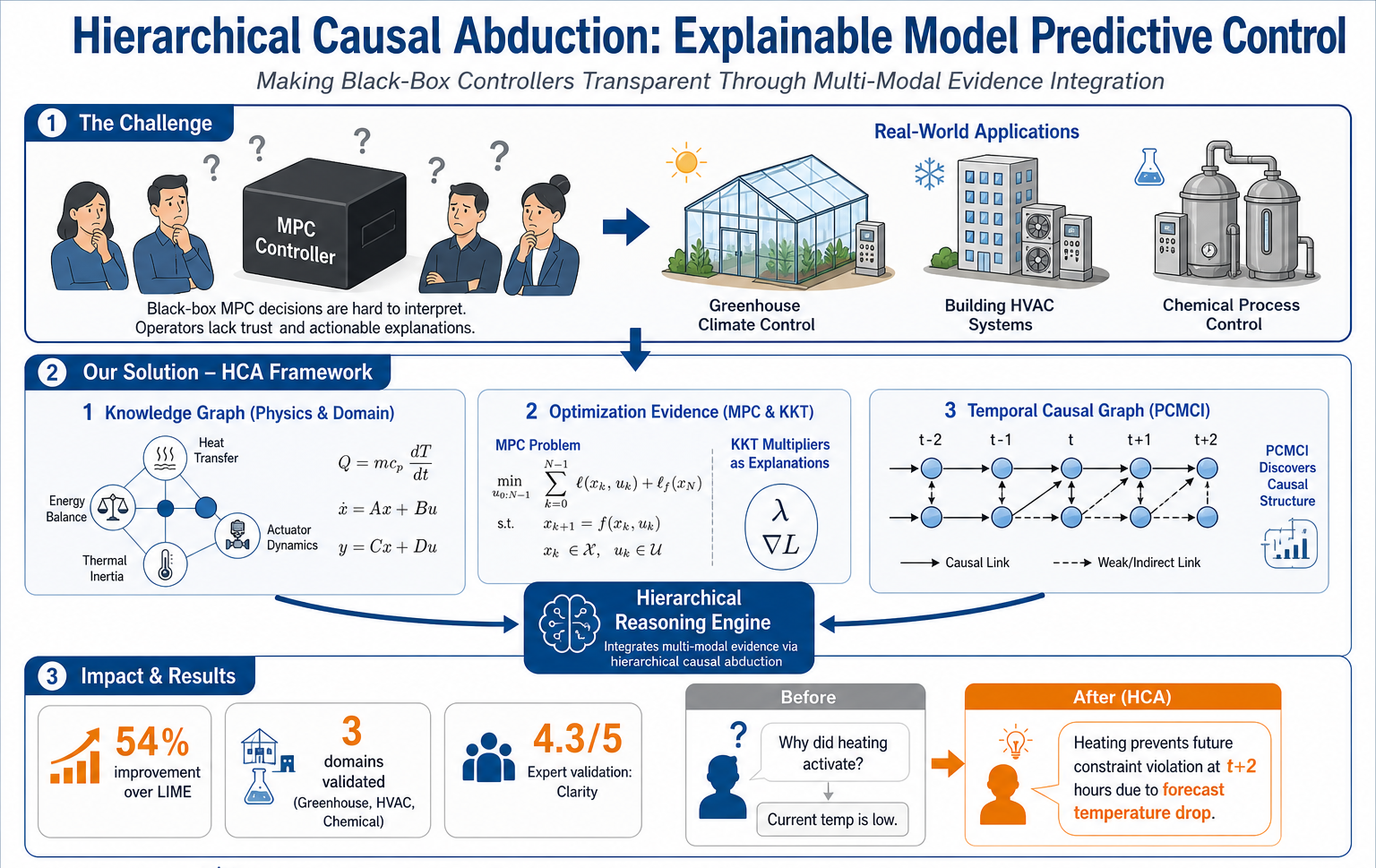
The earlier post on this blog, the mechanistic interpretability primer, ended on a promise. I said the techniques transfer cleanly to any transformer, including ones that have been adapted to reason about constrained control problems, and that I would write up what we actually find when we run the toolkit on such a model. This is that write-up. It is deliberately concrete and a little narrow, because the most useful thing I can offer here is a worked example, not a survey.
The setup, briefly. We take an open-weights base language model, fine-tune it on a curated corpus of control-theory papers, MPC textbooks, and worked examples of constrained optimisation, and use the resulting model as a reasoning interface inside the explainer described in our ICML 2026 paper. The model never replaces the optimiser. It reads the optimiser’s artefacts, like the active constraints and the multipliers, and turns them into language an operator can interrogate. The question of this post is what is actually inside that model when it does that job.
Three questions worth asking
The mechinterp toolkit is most useful when the question you bring to it is precise. Vague questions like “is the model interpretable” rarely produce useful answers. The three questions I keep coming back to in our setting are these.
Where does the model represent the notion of a constraint being binding. This is a binary distinction the optimiser already produces, and we want to know whether the language model has internalised it as a recognisable structure or whether it is reasoning about active constraints case by case. If there is a clean binding-or-not feature, we can use it as a probe everywhere we need to. If there is not, we are doing something more like prompt engineering than interpretation.
Where does the model represent the prediction horizon. MPC is fundamentally about acting now to prevent something later, and a faithful explanation of an MPC action almost always reaches across time. We want to know whether the language model carries any internal sense of “this is a stage-k consideration” or whether everything collapses into one undifferentiated “future.”
Where does the model store the difference between an objective term and a constraint. From the operator’s point of view, these are the same kind of thing, a number you push around. From the optimiser’s point of view, they are very different. A faithful explainer needs to keep them distinct, and we want to know whether the language model is doing that automatically or only when explicitly prompted.
What we find, in plain terms
For the first question, the answer is mostly yes. Sparse autoencoders trained on the residual stream at middle layers surface features that fire on tokens describing binding constraints across very different surface forms. The same feature lights up on phrases like “the cooling capacity limit is hit,” “the ventilation valve is saturated,” and the more textbook-style “the inequality multiplier is positive.” Ablating this feature degrades the explanations in a specific way, the model still names the constraint correctly but loses the language of it being binding. That pattern of degradation is the kind of evidence the field treats as compelling.
For the second question, the answer is a soft yes. There is a cluster of features that correlate with stage indices in the prediction horizon, but the cluster is smeared and the features are not as monosemantic as the binding-constraint feature. The model has a notion of “now versus later,” but it does not seem to have crisp internal coordinates for stage-1, stage-2, stage-3, and so on. This is roughly what I expected, and it is consistent with the model having seen many descriptions of horizons but few examples of explicit per-stage reasoning.
For the third question, the answer is the most interesting one, because the answer is “kind of, and the failures are diagnostic.” There are features that distinguish objective contributions from constraint contributions, but they are layer-specific. In early layers the distinction is clean. In middle layers it gets confused, especially on prompts where the user has phrased a soft constraint as a cost penalty. In late layers it cleans up again, but only after the model has used the surrounding context to disambiguate. That layered trajectory is itself a finding. It tells us where in the network the real disambiguation happens, which tells us where to look first when an explanation goes wrong.
What this is good for
None of the above is meant to be a self-contained scientific result. The point is methodological. If you treat a domain-adapted language model as a black box that “either explains things well or it does not,” you have nothing to do when it fails except retrain it. If you treat it as a network with features and circuits that you can name, probe, and ablate, every failure becomes a localisable bug. The binding-constraint feature is robust. The horizon features are smeared. The objective-versus-constraint distinction is layer-dependent. Each of those statements is actionable in a way “the model sometimes hallucinates” is not.
The other thing this work is good for, and the reason it is on this blog rather than in a paper yet, is that it gives a concrete answer to a question I get a lot. The question is whether mechanistic interpretability is “ready for engineering.” My honest answer has been “yes for transformers, with caveats, and only if you ask precise questions.” The work above is the version of that answer with receipts. Sparse autoencoders, residual-stream probes, and targeted ablations are not magic, but they are tractable, and on a model that has been trained on a domain you understand, they tell you things you can use.
What is next
The next step is to use the binding-constraint feature as a hard signal inside the explainer itself, rather than as a diagnostic on the side. If the language model has a clean internal indicator of when a constraint is binding, we should be able to lift that indicator out and use it as a verification check on the explanations the model produces, in addition to the KKT-based check the optimiser already gives us. Two independent signals on the same property is the kind of redundancy that turns a research prototype into something a practitioner can trust.
I will write that up when we have the numbers. The mechinterp primer remains the right starting point if you are coming to this fresh, and the paper-walkthrough post is the right next read if you want to see how this language-model interpretability work fits into the larger framework.
]]>